Browser Search
Browser Search is a zero-configuration deep search capability built into the SingWork Gateway. It requires no API Key and automatically performs web search, page parsing, content extraction, and result return via the built-in Chromium browser, providing stable, high-quality real-time information access for users both inside and outside mainland China.
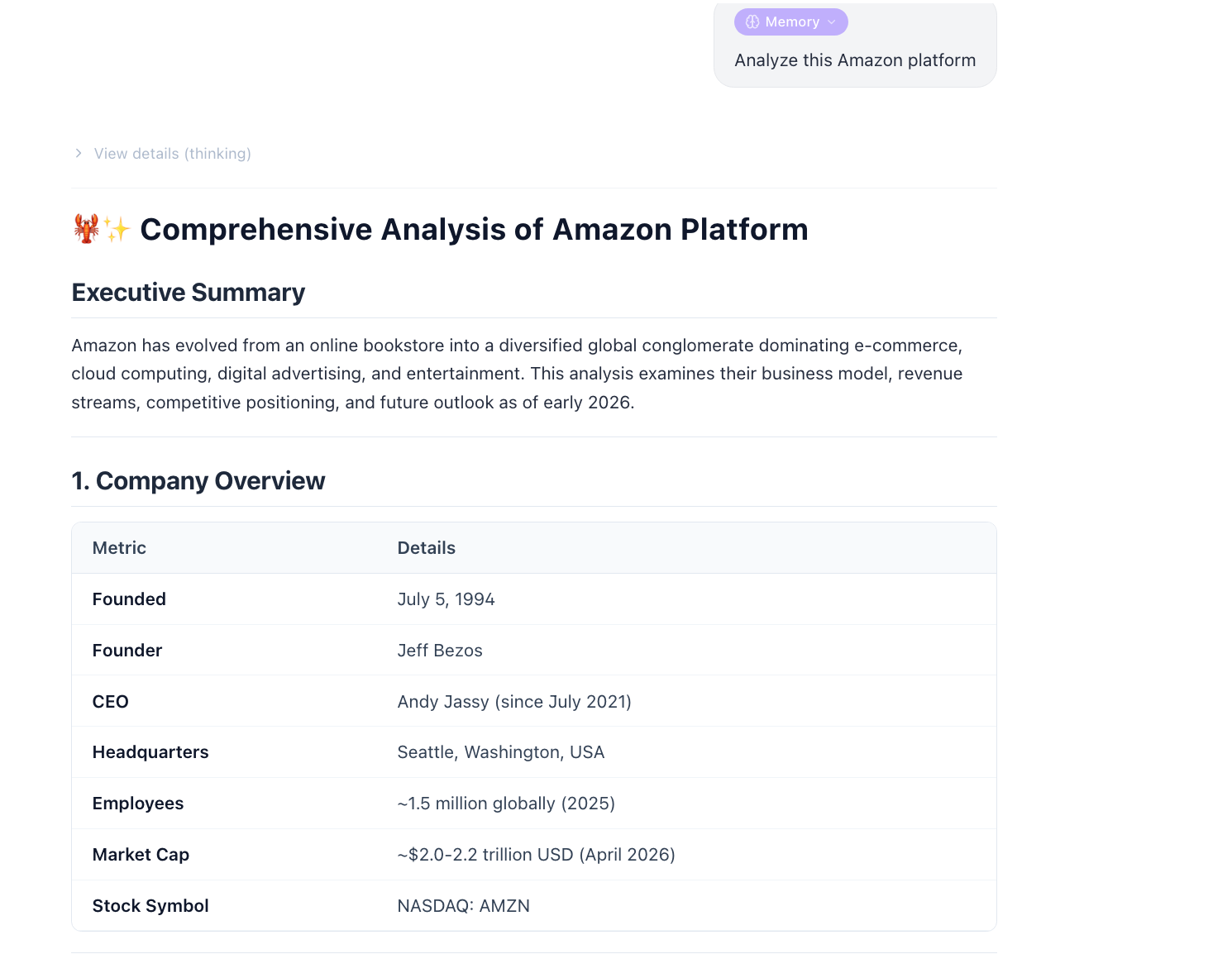
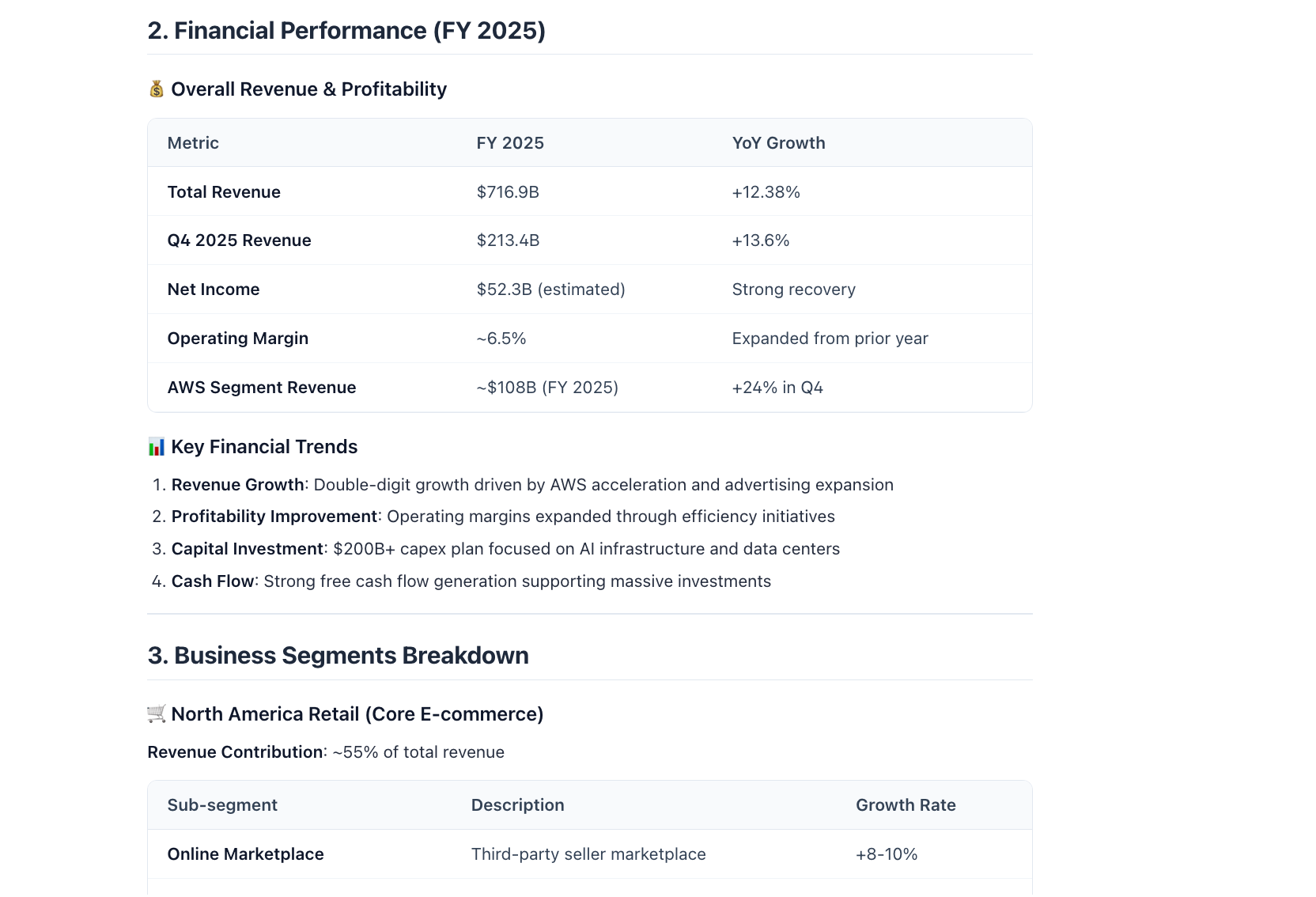
Core Functionality Flow & Experience
When a user asks a question requiring web lookup, the system automatically executes the full workflow:
- Task Understanding & Search Planning: The Agent automatically parses requirements and generates multi-angle search keywords.
- Automatic Search Engine Selection: Intelligently chooses engines based on mainland China/overseas environments without manual switching.
- Ad Filtering & Content Extraction: Automatically removes ads, accesses pages, and extracts clean main content.
- Structured Result Return: Returns title, URL, snippet, and content to support direct report generation.
- Full Process Unattended: One-stop completion from search to summary with real-time progress display.
Core Capability Modules
1. Zero-Configuration Automatic Search
- No API Key Required: Out-of-the-box, independent of third-party keys.
- Automatic Environment Detection: Identifies mainland China/overseas mode based on time zone, locale, and network status.
- Automatic Engine Fallback: Switches to the next available engine if the current one returns no results or fails.
- Mainland China Engine Chain: Bing China → 360 Search → Baidu → Sogou.
- Overseas Engine Chain: Google → Bing International → DuckDuckGo.
2. Deep Content Extraction
- Automatic Ad Link Filtering: Identifies and skips advertising, promotion, and tracking links.
- Anti-Crawl & Error Page Detection: Automatically skips login walls, 403, 404, 5xx, and other abnormal pages.
- Smart Body Extraction: Filters out navigation, footers, ads, and retains core content.
- Fallback on Extraction Failure: Falls back to search snippets if crawling fails, ensuring usability.
3. Search Caching & Performance Optimization
- LRU Cache Mechanism: Returns cached results immediately for repeated queries within 5 minutes.
- Human Behavior Simulation: Adds proper access delays to reduce blocking risks.
- Concurrent Page Extraction: Supports simultaneous crawling of multiple pages for efficient deep search.
- Result Truncation Control: Automatically limits per-page content length for stable, efficient responses.
4. Standardized Results & Compatibility
- Uniform Output Format: Returns standardized structure with
title,url,snippet, andcontent. - Compatible with Existing Plugins: Works directly with Agents without modification.
- Baidu Redirect Handling: Automatically resolves encrypted links to obtain real target URLs.
- User-Friendly Error Messages: Returns clear prompts when engines are unavailable for easy troubleshooting.
Typical Use Cases
- Enterprise / Industry Information Research: Automatically investigates business, products, financial reports, and competitor moves.
- Real-Time Information Access: News, policies, event progress, and impact analysis.
- Knowledge & Data Supplement: Retrieves latest documents, data, reports, and technical materials.
- Mainland China No‑API‑Key Scenarios: Provides stable web search for users without API keys.
- Automated Report Generation: Summarizes multi-round searches and outputs structured analysis directly.
Core Value Summary
SingWork Browser Search delivers zero-configuration, cross-environment, fully automated deep search capabilities. It solves pain points including cross-region network limitations, cumbersome API Key setup, cluttered search results, and difficult content extraction. It equips Agents with stable, high-quality real-time information access, truly achieving out-of-the-box, one-click deep search.